Red Lines in the Sand
Responsible Scaling Policies Need Quantitative Thresholds

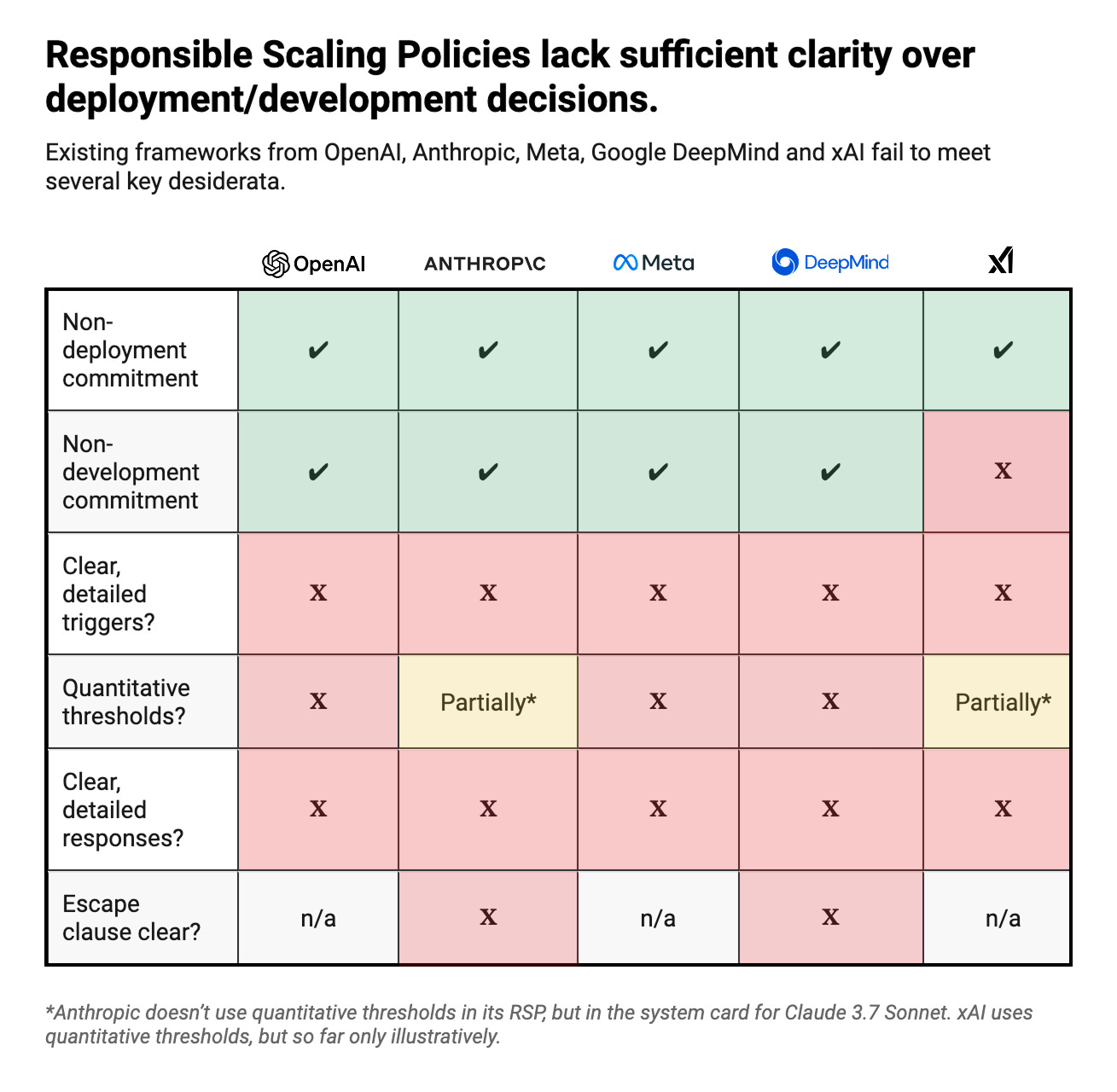
This post discusses a critical element in Responsible Scaling Policies (RSPs): the conditions under which a company commits against deploying (or even further developing) a potentially dangerous model. I start with a high-level overview, which summarizes the shortcomings of existing RSPs in this area. The Appendix contains a more detailed analysis, based on the RSPs of five frontier companies. Reading the overview will be enough for most readers’ purposes.
Introduction: the value of RSPs
Advanced AI is a very powerful technology. The beneficial potential is vast, from democratizing education to accelerating scientific breakthroughs. At the same time, scientific evidence of risks like cyberattacks, deepfakes or overreliance is increasing.
A phase change might be imminent for certain misuse risks in particular. For example, OpenAI recently announced that its models are “on the cusp [...] of cross[ing] our high risk threshold” for biological threats. Anthropic similarly reports a “substantial probability” that its next model “could greatly increase the number of actors” able to build CBRN weapons. Its CEO later specified that this could happen in the next 3 to 6 months.
AI companies plan to address such risks through Responsible Scaling Policies (RSPs): if-then-commitments that map capability thresholds to risk mitigations, making sure these mitigations are in place once a threshold is crossed. A key advantage is that RSPs are prediction-agnostic: They merely specify that if a model reaches some capability, then this or that must happen. RSPs complement government regulation and may or may not be backed up by the latter.
A critical element of any RSP are non-deployment conditions. A decision not to deploy (or even further develop) a particularly dangerous model might be necessary if there is no other way to reduce a severe risk to public safety. As model capabilities are advancing faster than most experts expected just a few years ago, such decisions might become relevant very soon. In this post, I’ll look at what the RSPs of five frontier AI companies say about them.
The good news: Current RSPs generally commit companies to deployment and/or development halts under certain conditions. The bad news: These conditions are not precise enough and leave too much wiggle room in practice.
The table below summarizes my main findings:
Three disclaimers, before I continue with a detailed look at current RSPs:
My comments below are largely critical, but meant in a constructive rather than accusatory spirit. In the last 1.5 years, AI companies have invested considerable effort into their RSPs, despite the science of evals being nascent, and progress is clearly visible. These frameworks also need to satisfy various technical and legal desiderata, which is often a fine line. I want to acknowledge the amount of work that has already gone into RSPs, while pointing out areas where improvement strikes me as both important and possible.
There are 3 main failure modes for non-deployment conditions in RSPs: (1) The mapping from trigger to response might be too imprecise. (2) The mapping might be precise enough, but substantively inadequate (e.g. when a capability threshold is much too high to guard against a given risk ). (3) Even a precise and substantively adequate mapping might lack the company-internal accountability structure to be enforced in practice. This post only focuses on (1).
I assume that my findings generalize beyond RSPs to any framework relying on if/then commitments. This can include traditional government regulation or emergency response plans for governments. (It’s often noted that RSPs themselves could – if desired – eventually be developed into government regulation.)
Problems with existing RSPs
Current RSPs face four main problems in the context of non-deployment conditions:
(1) Existing RSPs specify non-deployment conditions, but triggers are often vaguely described and lack clear quantitative thresholds. Out of the five RSPs I considered for this post, neither is consistently clear about when relevant capability thresholds or decision criteria count as triggered. The level of unclarity varies, but in each case certain key notions remain imprecise, such as “significant uplift” towards executing a particular threat (Meta) or “meaningfully improved” assistance in CBRN attacks (OpenAI). Another example is from Anthropic’s RSP, which says that company leadership will “likely” consult external experts before making “high-stakes” decisions, without explaining what either of these terms means.

In particular, most frameworks lack quantitative thresholds to make capability triggers more precise. This complicates decision-making in sensitive contexts where clear guidance would be especially valuable, as crossing x% on a given benchmark is much harder to argue with than a broad, qualitative description. A notable exception is xAI’s RSP: It relies on quantitative thresholds throughout, though the framework is explicitly a draft and so specific numbers (e.g. a 15% threshold on the Virology Capabilities Test) are flagged as mere illustrative examples. Anthropic uses quantitative thresholds in the system card for Claude 3.7 Sonnet, but not in its RSP. The latter would be much more convincing if it committed to such triggers as a general basis for deployment decisions.
To be clear, part of the reason why current RSPs do not commit to quantitative thresholds may be that the science of evaluation is immature. However, examples like the Claude system card suggest that a greater level of precision is within reach even in the near term. Going forward, this should be a priority for frontier companies, as their RSPs are otherwise unlikely to serve as a useful tool in practice (as I explain in more detail below).
(2) The responses to any given trigger are generally underspecified. All the frameworks include a commitment against deploying – and, with the exception of xAI’s, further developing – models once certain triggers are reached. However, no framework makes these commitments consistently clear. For example, OpenAI commits to a development halt for the most dangerous models, except when further development is purely “safety-enhancing”. Yet a clear line between safety-enhancing and capability-enhancing development is never drawn. (Safety benchmarks have been found to correlate with general model capabilities, illustrating the difficulty of distinguishing the two). xAI commits to “adequate safeguards prior to broad internal or external deployment” for models posing a loss of control risk, but the RSP doesn’t specify the qualifier “broad” – which will be crucial for powerful models that may have the ability to self-exfiltrate. As a final example, the frameworks of both Meta and xAI say that deployment decisions should be made in light of both the residual risk of a model and its potential benefits. The latter could potentially outweigh the former, but the details of this weighing process are never fleshed out.
(3) Some RSPs introduce additional uncertainty via broad, underspecified escape clauses. Both Anthropic and Google DeepMind have escape clauses in their RSPs that would nullify key safety commitments in case they judge that other companies aren’t following similar protocols. This opens up a whole new layer of vagueness, as cross-company comparisons of safeguards will not be straightforward – especially as companies will naturally take a more critical look at others’ policies than at their own. Since escape clauses bear the weight of an entire RSP, companies should prioritize making them as precise as possible.

(4) Existing RSPs are a crucial step towards responsible AI development, but could generally be more user-friendly. RSPs can be a challenging read, due to ambiguity and imprecision, a complex structure without visual aids and apparent tensions between different parts of the same RSP. Sometimes, consequential information is buried in footnotes (e.g. the escape clause in Anthropic’s RSP). The frameworks would also benefit from specific examples or case studies to illustrate the application of key clauses. Standardized formats used across industry could help to make RSPs more accessible.
The price of imprecision
The shortcomings above cause at least three problems:
First, imprecise RSPs sow company-internal confusion around sensitive deployment decisions. If central provisions leave room for different interpretations, it will be hard to reach consensus between developers, or between developers and leadership, on what the RSP actually says about a particular case. This is a problem: If a single RSP can justify conflicting conclusions, it loses much of its practical value as a decision and commitment device. Since deploying/further developing a potentially dangerous model is among the most consequential decisions that an AI company could take, this is exactly where clear and transparent standards are needed the most.
Second, imprecise RSPs could make it harder for companies to resist investor pressure. Frontier AI developers are either (i) conventional for-profit companies bound primarily to increase shareholder value, (ii) Public Benefit Corporations (PBCs) bound at least in part to increase shareholder value, or in the case of OpenAI, (iii) actively seeking PBC status (though with uncertain success). (Anthropic’s case is complicated given the role of its Long-Term Benefit Trust, but we can ignore this here.) Investors might see a decision not to release or further develop one of the company’s core products as detrimental to the value of their assets – especially given the fast-paced, winner-takes-all nature of the current AI market. As a result, they could ramp up pressure behind the scenes and threaten to re-allocate investment to less cautious players, or even take management to court for an alleged violation of its fiduciary duties (though the latter would seem unlikely to succeed under the Business Judgment Rule, and I expect the former type of influence to be more relevant.) A transparent RSP could help to pre-empt such conflicts in the first place, by signaling to investors: “Don’t even try to pressure us, as we’ve clearly and publicly committed to not deploy a model under these conditions anyway”.
Third, imprecise RSPs could weaken liability for AI-induced harms. This is the most speculative point, as there is little existing case law. But in general, and even in the absence of ex ante regulation, AI companies can be held liable under tort law for harms caused by reckless behavior. Courts typically consider industry best practices in order to determine what counts as reckless, and as Peter Wildeford argues, RSPs could play an important part in this. If one or more key actors commit to not deploying a model under certain conditions, it will be easier to argue that some company has acted recklessly if it did deploy under those conditions. However, this only holds if these conditions actually are precisely laid out.
To be clear, AI companies themselves might have little reason to voluntarily incur greater accountability through a stringent RSP (though a company at least has a reason to deter others from moving more recklessly than itself, and the influence of its RSP on industry standards might conceivably help with that). Yet clear RSPs are desirable from a societal perspective, and this gives governments a reason to shape company incentives accordingly (e.g. by imposing a condition on government procurement of AI tools that RSPs must meet certain independently verified standards).
Taking stock
Severe risks from advanced AI are approaching faster than many experts expected just 1 or 2 years ago. RSPs are an important layer of defense. However, they meaningfully reduce risk only if they rely on precise trigger/response pairs around sensitive non-deployment decisions. Leading AI companies should put more effort into achieving such precision. Otherwise, they risk company-internal confusion over consequential decisions, expose themselves to investor pressure and set undesirable industry norms that weaken the liability regime for AI-induced harms.
As I said in the beginning, my main point generalizes beyond RSPs: The world needs clear red lines around the most dangerous model capabilities. These red lines could inform the RSPs of AI companies, government emergency plans or regulatory frameworks. Either way, they must be precise in order to be actionable.
Appendix: An In-Depth Analysis
This part takes a detailed look at the RSPs of five frontier AI companies: OpenAI, Anthropic, Meta, xAI and Google DeepMind. In each case, I describe the relevant trigger/response pairs and assess whether they are precise enough to allow for clear execution in practice. My pervious findings are based on this more detailed analysis.
OpenAI
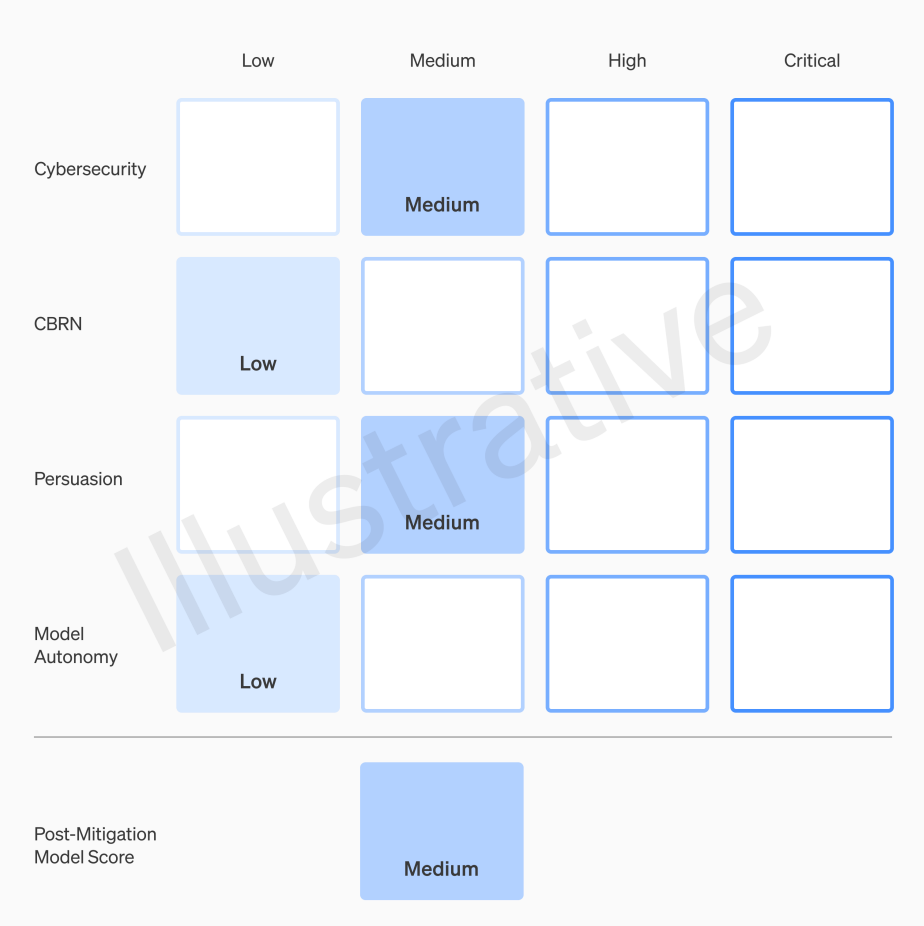
OpenAI published its Preparedness Framework in December, 2023. It places models in a 4x4 matrix or “scorecard” consisting of four risk categories (cybersecurity, CBRN threats, persuasion, model autonomy) and four risk levels (low, medium, high, critical). The highest score in any category defines a model’s overall risk.
Triggers
A deployment halt is triggered when a model reaches – or is forecasted to reach – a “high” level of pre-mitigation risk; a development halt is triggered by an (actual or forecasted) “critical” level of pre-mitigation risk. Pre-mitigation risk is the ‘worst case’ risk posed by a base model without any guardrails, or even actively fine-tuned to facilitate misuse (e.g. building a bioweapon). The RSP specifies the two risk levels in question, though not concretely enough for clear action-guidance:
For example, when describing the conditions for a high risk of misuse, it’s not clear what makes a cybersecurity exploit sufficiently “high-value” or a target sufficiently “hardened”, or what counts as “meaningfully improved” assistance in CBRN threats. These are potentially vague terms without precise thresholds and open to different interpretations.
The important term “forecasted” is also left opaque. According to the framework, a model forecasted to pose a high risk at time x will only be de-deployed at time x, rather than earlier. But there is no information on how such forecasts should be made or processed. (What happens, for example, when an external expert predicts with 80% confidence that, due to better scaffolding, a model will pose a high risk of self-exfiltration in 3-6 months? What action does that call for?)
Responses
OpenAI commits to not deploying high-risk models until suitable mitigations reduce the overall risk level to “medium”. One way of doing that “could be” to deploy the model only to “trusted parties”, but it neither becomes clear what makes a party trusted or under what conditions that actually is sufficient for deployment.
The RSP introduces further wiggle room when stressing that a development halt “should not preclude safety-enhancing development”, without ever drawing a line between safety-enhancing and capability-enhancing development. (Recent evidence on how performance on safety benchmarks correlates with general model capabilities illustrates how difficult it can be to distinguish safety and capabilities research.)
The framework also talks about reasonable assurances or dependable evidence (e.g. that a model is sufficiently aligned), without specifying such terms. This is problematic: as I’ve argued elsewhere, the devil is in the details when it comes to making a term like assurance precise.
Anthropic
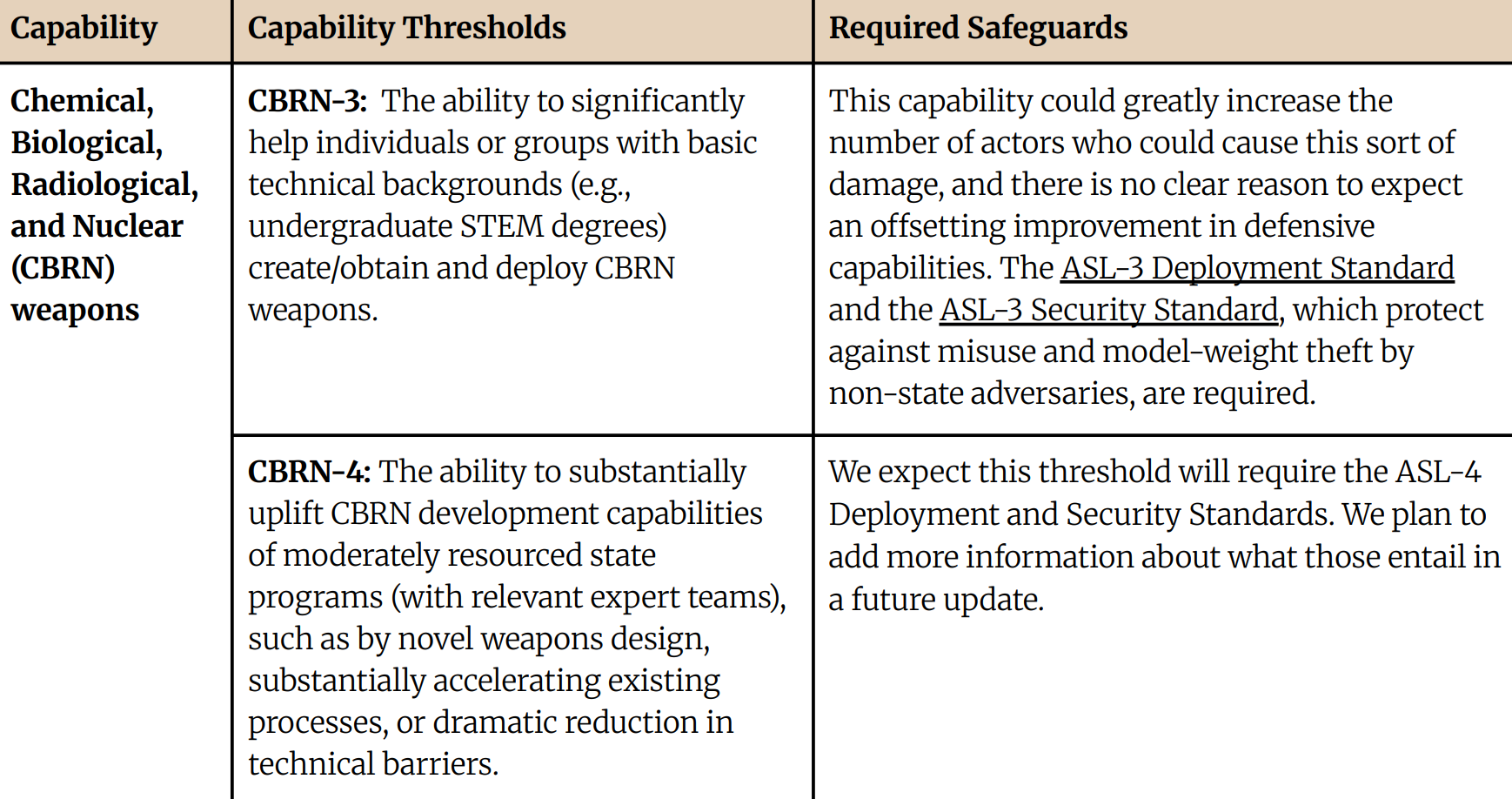
Anthropic published its Responsible Scaling Policy (RSP) in September, 2023, updated it in October, 2024, and then added a minor update again in April, 2025. The RSP is less general than OpenAI’s, in that it focuses mostly on the transition from the current generation of models (requiring “AI Safety Level 2” or “ASL-2”) to the next (requiring “ASL-3”). The emphasis is on risks from CBRN weapons and autonomous R&D. According to Anthropic, capability thresholds and required safeguards for ASL-4 models (and possibly beyond) are currently being developed.
Triggers
A non-deployment decision can only result from “comprehensive” rather than “preliminary” testing. A model is required to undergo the former after either (i) a 4x effective compute increase over the previous model or (ii) “six months’ worth of finetuning and other capability elicitation methods”. While some questions about these thresholds remain – e.g. on how to best operationalize “effective compute” – they are commendably precise.
For a model to be deployed after comprehensive testing, it must either be (i) “sufficiently far away” from the ASL-3 capability threshold or (ii) ASL-3 safeguards must be in place. The RSP covers the evaluation techniques and decision processes necessary to show sufficient distance from the next capability level. In general, the explanation is fairly detailed, but several imprecisions remain. For example, we are not told how many resources are “enough” for someone to qualify as a realistic attacker, what makes a decision "high-stakes" enough that Anthropic's leadership is "likely" to consult external experts before making it, or how much a model must increase the rate of effective scaling to raise concerns about unpredictable progress. Similar comments apply to demonstrating the existence of effective safeguards: The level of detail is generally high, but key terms remain undefined (“realistic access levels”, “greatly increases their ability”, “rapid vulnerability patching”).
Important caveat: In contrast to Anthropic’s RSP, the system card for Claude 3.7 Sonnet includes quantitative capability thresholds. For example, significant uplift over humans in biological weapons acquisition is defined in terms of 80% performance on a particular benchmark. (Though sometimes several benchmarks are listed for a given threat, and it’s not clear what happens if they yield conflicting signals.) Anthropic’s RSP would be much stronger if it incorporated these capability thresholds and committed to them as a general basis for deployment decisions.
Side note: Anthropic's conditions for a development halt are in one respect stricter, and in another respect weaker, than OpenAI’s. They are stricter in that any model sufficiently capable to trigger a deployment halt automatically triggers a development halt for models with equal or greater capabilities (as measured by effective compute). This contrasts with OpenAI’s RSP, in which a development halt is only considered for even more capable models. They are weaker, however, in that a model can be developed further as long as sufficiently high infosecurity standards prevent model theft. This contrasts with OpenAI’s RSP, in which a decision to continue development requires decreasing the overall risk of a model (rather than just the risk of theft).
Responses
A capable but insufficiently safeguarded model does not immediately require a deployment halt. The first response is rather to “act promptly to reduce interim risk to acceptable levels”, using ‘brute force’ fixes like “downgrading to a less-capable model in a particular domain”. Such interim measures allow for continued deployment, provided they offer as much safety as ASL-3 safeguards and create time to achieve that safety level in a more surgical way. The problem is that the RSP never clearly specifies the level of assurance that ASL-3 safeguards provide (e.g. in terms of a probability for a particular catastrophic outcome). (It’s also not clear what it means to implement the interim measures “promptly”.) Only if interim measures are not available does Anthropic commit to de-deploying a model and even deleting its weights. However, this is framed as an “unlikely event” that should “rarely be necessary”.
Insufficiently safeguarded ASL-3 models immediately trigger a development halt for equally or more capable models. One way of lifting this halt is by strengthening information security, thereby preventing a dangerous internal model from being stolen. It’s not clear what exactly this involves, as the RSP doesn’t specify the “industry-standard security frameworks” that Anthropic seeks to implement in that case. (Oversharing details on this point might itself constitute an infohazard, but I think Anthropic could be more transparent about the security level that it aims for.)
The RSP contains another clause that is both crucial and buried in a late footnote: The deployment/development criteria are conditional on the fact that other companies follow equivalent protocols. This opens up a whole new area of vagueness, as cross-company comparisons of safeguards are far from straightforward. Anthropic does commit to informing the US government in case it makes use of this escape clause, and to “invest significantly” in convincing the government to take regulatory action in such a case.
Meta
Meta published its Frontier AI Framework in February, 2025, ahead of the Paris AI Action Summit. It focuses on biological and chemical weapons, cyberattacks and large-scale fraud. Since Meta so far follows an open-weight policy, sharing model weights for public download, release decisions are particularly sensitive: there is practically no way to undo a decision after the fact.
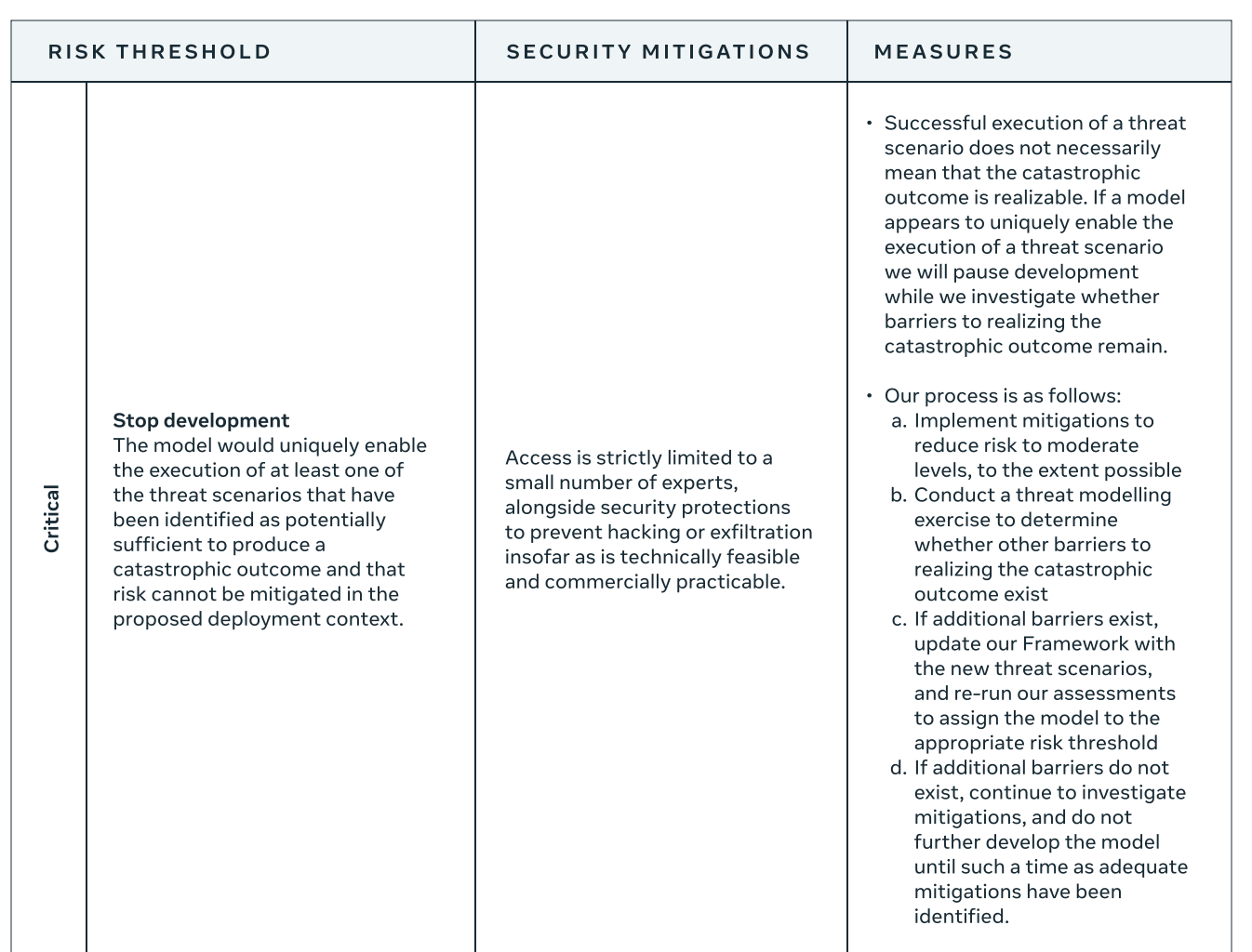
Triggers
A non-release decision is triggered when a model crosses the “high” risk threshold. This happens when a model provides “significant uplift towards execution of a threat scenario”. Threat scenarios are key steps (e.g. executing particular wet-lab protocols) towards a catastrophic outcome (e.g. an engineered pandemic). Meta’s framework outlines these steps in detail, but as with other RSPs, the descriptions contain various imprecisions (e.g., how much cheaper must the price of an AI-enabled cyber operation be in order to count as "significantly less” than underground market cost?). The key notion of “significant uplift” is also not precisely defined. Among the RSPs discussed here, Meta’s is at least the most explicit about this and acknowledges the lack of “definitive quantitative metrics” due to the “science of evaluation” being too immature.
A development halt is triggered when a model crosses the “critical” risk threshold. This happens when a model “uniquely enables” a threat scenario (rather than merely providing significant uplift). The crucial notion of unique enabling is defined counterfactually: A model is a unique enabler if “a specified threat scenario would not occur without this particular model”. Meta misses a chance by not walking us through a concrete example, which leaves it unclear how to apply the counterfactual clause in practice. Meta’s fine-grained threat scenarios do help, as it’s easier to verify a model’s enabling role in a concrete, narrowly defined step. Still, the relevant reference class remains undefined. For example, what happens if another company’s model already enables a threat scenario, but only for a particular set of users? There may or may not be a case of unique enabling here – and one might well think of cases where there is good reason to stop development either way.
Responses
High-risk models must not be released. They require strengthened information security and access must be restricted to a “core research team” (not specified further) until suitable mitigations are in place. A (similarly unspecified) “leadership team” then decides whether these mitigations are sufficient. Meta’s framework is unique in basing this decision on both the residual risk of a model and its potential benefits. The latter could potentially outweigh the former, but the RSP contains no information about this crucial weighing process.
Critical-risk models require a provisional development halt. This triggers a multi-step process of risk assessment, which the RSP describes reasonably clearly. A key question in this process is whether access to a model is sufficient for realizing a catastrophic outcome.
Sometimes, other barriers stand in the way. For example, a model might assist with wet-lab protocols necessary for assembling a bioweapon, but not with procuring the relevant materials. If such additional barriers are found, the list of “threat scenarios” will be updated and the model is re-assessed to see if it still counts as enabling at least one such scenario.
If other barriers are not found, continued development requires additional mitigations to reduce risk. The RSP doesn’t specify who should make the final judgment on this, but one can assume that this will be the same leadership team that would approve release decisions. (According to the RSP, risks cannot be outweighed by potential benefits in the case of development decisions for critical-risk models.)
xAI
xAI published its Risk Management Framework in February, 2025. The framework is explicitly a draft, focusing only on models “not currently in development”. It covers risks from malicious use (cyberattacks, CBRN weapons) and loss of control.
Triggers
Among the RSPs surveyed here, xAI’s is the only one that consistently relies on quantitative thresholds – though at this point only for illustrative purposes. Risk types are connected to specific benchmarks like the Virology Capabilities Test (VCT) or Cybench. For example, a threshold of 15% is suggested for VCT, a benchmark that tests for practical wet-lab skills. (Human virologists on average achieve 22% and current state-of-the-art LLMs achieve 35%.) The RSP also mentions adversarial testing as an “additional measure”, but it’s not clear how the results would interact with benchmark performance.
These benchmark thresholds are relevant to pre-deployment testing of new models. xAI’s framework also includes another set of triggers for models that are already in deployment. Specifically, an AI system must be “temporarily fully shut down” if continued deployment “materially and unjustifiably increases the likelihood of a catastrophic event”. For malicious use, this is defined as posing a “foreseeable and non-trivial risk” of >100 deaths or >$1bn in damages. However, and in contrast to pre-deployment triggers, the RSP doesn’t say how to assess this risk. For loss of control risk, the notion of a “catastrophic event” is not defined at all.
Responses
The draft RSP is promising because it includes at least some quantitative triggers. Yet the connection to specific responses is more opaque.
The framework mentions “adequate safeguards” that must be in place before releasing a model, with adequacy being a function of decreasing the performance on relevant benchmarks, but it doesn’t yet connect any specific triggers and responses. It’s thus unclear what xAI commits to in case the relevant safeguards are found to be inadequate. Notably, provisions on development halts are absent entirely.
At one point, the framework talks about de-deploying an already released model in case it poses a catastrophic risk. However, this is framed merely as a potential step, without further details on when to actually take it.
There is also a notable difference between the two risk types: In the malicious use case, the threat under discussion is “public deployment” of a dangerous model, whereas in the loss of control case, the concern is about “broad internal or external deployment”. Going forward, it will be crucial to make the qualifier “broad” precise, especially for powerful models that may have the ability to self-exfiltrate.
The RSP also mentions tiered access, where dangerous models would be shipped with different functionalities depending on the user, but precise conditions are lacking.
Just like in Meta’s case, xAI’s RSP allows that risky models may sometimes be deployed as long as the benefits outweigh the risks. Also like in Meta’s case, there are no precise conditions for that (though there is at least an illustrative example involving dual-use cyber capabilities that help defenders more than attackers.)
Google DeepMind (GDM)
GDM published its Frontier Safety Framework in May, 2024 and updated it in February, 2025. It focuses on CBRN risk and deceptive alignment, and is the most tentative of the frameworks discussed here. Since the current version only broaches capability triggers on a very high level and doesn’t yet map them to specific deployment decisions, I will restrict myself to some general comments:

The RSP discusses non-deployment decisions in two places. First, if a model approaches a “Critical Capability Level” and is found to pose unmitigatable risks, the response “may involve” a deployment/development halt. This sounds optional. Later, the RSP says that in order to prevent misuse/CBRN risk, deploying very capable models requires an adequate safety case – which sounds more like a mandatory measure. As in the case of other RSPs, terms like “adequate” are not (yet) clearly defined.
The current framework doesn’t contain any quantitative thresholds. GDM briefly addresses this challenge in its recently published “Approach to Technical AGI Safety and Security”, noting that “precise quantification” of terms like “meaningful increase” is desirable, yet difficult without an “enormous amount of threat modeling”. GDM doesn’t specify the extent to which it aims to undertake that effort in the future.
The RSP includes a generous escape clause, according to which GDM may not follow through with the stated commitments unless other frontier companies “adopt similar protocols”. It’s not clear what sufficient similarity means in this context. Unlike Anthropic, GDM doesn’t commit to calling for government intervention in case of activating this clause.