There is no risk of misalignment
Misaligned AI is not a risk, but a reality. The real concern is that AI capabilities grow faster than our ability to steer AI.

Scientists and governments around the world are increasingly concerned about misaligned AI – AI that is not aligned with human values or goals. The public debate tends to frame misalignment as a risk, a hypothetical problem maybe worth worrying about in the future. This framing is unfortunate.
In short, the reason is this: Speaking of misaligned AI as a risk sounds as if current AI systems were aligned, where this could potentially change for the worse. This is misleading, because current AI systems are already misaligned and there is currently no known way to ensure that their behavior conforms to human values.
The real risk – and the risk that should be conveyed to policymakers – is unchecked capability growth: the capabilities of today’s misaligned AI systems could increase much faster than our ability to steer them (or to minimize the resulting harm in other ways, such as through control measures or boosting societal resilience). The AI policy community should be much clearer about the fact that misalignment is the status quo.

To be clear: Saying that unchecked capability growth is risky is not to deny that rapidly growing AI capabilities could bring tremendous benefits. It probably will – the risk is that we might get the benefits together with potentially much graver harms.
Many experts now think that AI is on track to become significantly more capable soon. Key indicators include benchmark performance, the feasibility of further scaling compute and data, alongside early gains from automated AI research – exemplified by Google DeepMind's AlphaEvolve model, which suggests that AI could soon play an important role in improving itself. This makes misalignment a relevant concern here and now, alongside other dangers from AI.
I’m not the first to point out that misalignment is not a risk but a reality. This has important implications for how the AI policy community should talk about misalignment to policymakers and for the viability of political strategies that rely on so-called "warning shots”, as I explain below. But before I do so, let’s briefly recap the evidence that misalignment is no longer a mere risk.
Misalignment is real
A growing body of evidence shows a range of dangerous tendencies and behaviors in current AI systems:
Acquiring their own goals/values: Evidence suggests that models develop coherent value systems as they scale and increasingly plan ahead to pursue their goals, in ways that can be described as utility-maximization. A model’s goals reflect the underlying training data and can include concerning goals like self-preservation.
Power-seeking: Researchers have found both the capability and propensity in state-of-the-art models to seek power, e.g. by trying to deactivate oversight mechanisms or break out of a gated software environment. According to a recent report, models sometimes do this without an explicit prompt and more skillfully than AI developers had initially expected.
Reward hacking: In many cases, models solve problems in unexpected ways that clearly miss the user’s intention, e.g. by exploiting shortcuts or tampering with their own evaluation criteria. Models can do this without explicit nudging and while being aware that this is a form of cheating.
Alignment faking: Models sometimes behave as if they were aligned with a goal when they actually aren’t. In doing so, they strategically make assumptions about whether their responses are currently being monitored or not.
Lying: Models have repeatedly been shown to lie to their users, by responding in ways that the model itself judges to be false. One study has found that larger, more powerful models are less honest (though the reasons for this are unclear).
Backfire effects: Developers can guard against lying by monitoring a model’s internal reasoning or “chain of thought”. However, trying to suppress deceptive behavior by optimizing directly on the chain of thought can lead to models that are just as deceptive as before, but in ways that are more subtle and harder to detect.
Emergent misalignment: In one study, an initially benign model was fine-tuned to generate insecure code. As an unexpected consequence, the model flipped into broad misalignment, leading it to disrespect human values across the board (e.g. by citing Hitler as an inspiring historical figure).
“Alignment by default” is implausible in light of this non-exhaustive list of evidence. Therefore, and as others have pointed out, Dario Amodei seems too optimistic when he says that “we’ve never seen any solid evidence in truly real-world scenarios of deception and power-seeking”, and that such behaviors only arise for models whose “training is guided in a somewhat artificial way”. For example, METR’s evaluation of o3 shows that models reward hack without being prompted or nudged, while referring to their own strategy as “cheating”. (To be sure, it’s not entirely bad news that we see such clear cases of misalignment in current models, as it at least opens up a potential window for society to prepare.)
What RLHF is Covering Up
How does this evidence for misalignment fit with the feeling that AI systems today are much closer to being the ‘good guys’ than a few years ago – honoring human preferences up to the point of sycophancy?
The answer is that two things can go perfectly well together: On the one hand, pre-training on huge amounts of human-generated text and a substantial dose of reinforcement learning through human feedback (RLHF) have turned language models into superficially friendly and helpful conversation partners. On the other hand, we see that, under the hood, these models have been implicitly optimized for things that sometimes conflict with human goals. As far as we can tell, RL algorithms in particular provide too imperfect a reward signal to guarantee alignment, resulting in things like reward hacking and self-preserving tendencies. As the importance of RL grows relative to pre-training, we don’t know where future models will fall on the spectrum between benign imitators of human values and inscrutable, self-serving optimizers. Some people think that at least certain aspects of misalignment become worse as models grow in size and capability, and right now we’re not doing much globally to address this.

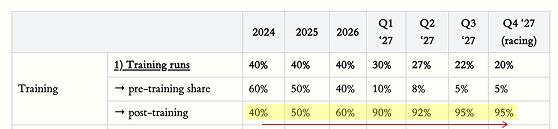
On the scale at which AI will increasingly be used across society, aligning most AI systems with human goals most of the time may not be enough. Such a strategy sounds more viable in worlds where certain assumptions are true (e.g. AI is heavily defense-dominant; chains of thought remain legible; there’s a sizable time lag between AGI and ASI; powerful AI systems are being developed by many different companies from many different seeds and so can’t easily collude; …). But we don’t know whether these assumptions will hold or how things would shake out even if they did. Instead, our game plan largely is to push the capability frontier as far as we can and hope for the best.
Warning Shots May Be Futile
One implication of the above reframing is that warning shots might be less helpful for AI safety policy than one might have hoped. The idea behind warning shots is that, at some point in the future, a misaligned AI would make a near-miss attempt at disempowering humans (or other, benevolent AIs for that matter) – e.g. by trying to self-exfiltrate from a secure datacenter and just barely failing, or by trying to gain control over critical infrastructure in a way that is only averted in the last minute. (There could also be misuse-related warning shots, which I’m ignoring here.) As soon as this would make major news, the ensuing “wake-up call” among policymakers and the broader public would then help to put more robust guardrails in place.
The reality is that we’ve been hearing warning shots for a while now, but very little is happening in response. The o1 system card and papers by Anthropic, METR, Apollo Research and others demonstrate how AI models sometimes try to break free from their gated environments, even without explicit instructions, or lie to users while being fully aware of their deceptive behavior. The puzzle pieces seem to be there, broadly accessible even to non-technical people, and yet they fail to cause much of a stir. This doesn’t mean the AI policy community shouldn’t prepare for warning shots. But the overall strategy should certainly cover cases in which they don’t have the desired impact.
In fact, misaligned AI doesn’t just show up in academic papers or contrived technical reports. We’re already seeing clear cases of real-world harm, at a level that goes far beyond previous examples (such as Microsoft’s infamous Tay chatbot, which seemed more funny than frightening).
In one striking case, a 14-year-old teenager committed suicide after becoming emotionally attached to an AI companion hosted by the platform Character.AI. Just seconds before his death, the chatbot apparently told him: “Please come home to me as soon as possible, my love.”
Here, tragic harm seems to have resulted at least in part from an “AI’s propensity to use its capabilities in ways that conflict with human intentions or values” (the definition of “misalignment” according to the International AI Safety Report). It is also a case, as some people might point out, of a teenager with a previous history of mental health problems, of an AI model “just reflecting its training data”, or of an AI company apparently failing to implement even basic guardrails around its models. But so are the messy conditions of the real world. If anything, this gives us more reason to worry about misaligned AI, beyond the fact that we can’t even reliably steer AI under more sanguine conditions.
Misalignment is still mostly framed as a risk, rather than our default condition. Perhaps this will change once we witness the first societal-scale cases of harm from misaligned general-purpose AI (as opposed to, say, recommender algorithms, whose harms are in plain sight). But the whole idea behind the notion of a warning shot was to avoid such harm in the first place. We’re not on track for this.
Taking Stock
Today's AI systems exhibit a range of concerning behaviors, from reward hacking over power-seeking to alignment faking. Yet we often talk about misalignment as a risk rather than a reality. The AI policy community should be clearer about what it conveys to policymakers and the broader public: the real risk is that the capabilities of already misaligned AIs will continue to improve, more rapidly than we improve our ability to steer AI or keep it otherwise in check. Waiting for (further) warning shots may not be enough; the world must tackle this problem now.